
Cohere AI Crawler (cohere-ai): What Website Owners Need to Know (2026)
Cohere is one of the most important AI companies that many website owners have never heard of. Unlike ChatGPT or Google, Cohere does not have a consumer product that people use daily. Instead, it builds AI infrastructure used by thousands of businesses worldwide. And its web crawler, cohere-ai, quietly crawls millions of websites to collect training data for these enterprise AI models.
For website owners, the Cohere crawler presents a different kind of decision compared to consumer-facing AI crawlers. There is no direct search benefit or citation traffic from allowing it. But Cohere's models are used by major corporations for customer support, internal search, and document processing, which means your content could influence enterprise AI applications that serve millions of business users.
Start by checking your current settings. Use the AI crawler checker free tool to see if Cohere's crawler can access your website right now.
What is Cohere?
Cohere is a Canadian AI company founded in 2019 by former Google Brain researchers, including Aidan Gomrat, who co-authored the landmark "Attention Is All You Need" paper that introduced the Transformer architecture (the "T" in GPT). Cohere is headquartered in Toronto and has raised over $1 billion in funding.
Unlike OpenAI (which focuses on consumer products like ChatGPT) or Anthropic (Claude), Cohere focuses primarily on enterprise AI infrastructure. Their products are designed for businesses that need to integrate AI into their own applications and workflows.
Cohere's Key Products
Command
Cohere's flagship large language model for text generation, summarization, and conversational AI. Used by enterprises for customer support, content creation, and data analysis.
Embed
A text embedding model that converts text into numerical representations for search, clustering, and classification. Used by companies to build semantic search engines.
Rerank
A specialized model that re-orders search results by relevance. Used to improve the accuracy of enterprise search systems and RAG (Retrieval-Augmented Generation) applications.
Aya
Cohere's multilingual AI model supporting 100+ languages. Built through a global research collaboration, it enables AI applications in non-English markets.
The Cohere-AI Crawler: Technical Details
Cohere's web crawler identifies itself with the following user agent string in your server logs:
The cohere-ai crawler is used to collect web content for training Cohere's suite of AI models. Here are the key technical details:
Compared to more aggressive crawlers, Cohere's bot is one of the better-behaved AI crawlers. It does not flood servers with requests and respects rate limiting directives.
What Data Does the Cohere Crawler Collect?
The cohere-ai crawler collects publicly accessible web content for model training purposes. This includes:
Text content: Articles, blog posts, documentation, product descriptions, and other textual content on public web pages.
HTML structure: Page structure, heading hierarchy, and semantic HTML elements that help the AI understand content organization.
Metadata: Title tags, meta descriptions, and structured data that provide content context.
The collected data is used to train Cohere's models across multiple capabilities: language understanding, text generation, semantic search, and multilingual processing. Because Cohere serves enterprise customers, the quality and diversity of training data directly affects how well their models perform for business applications.
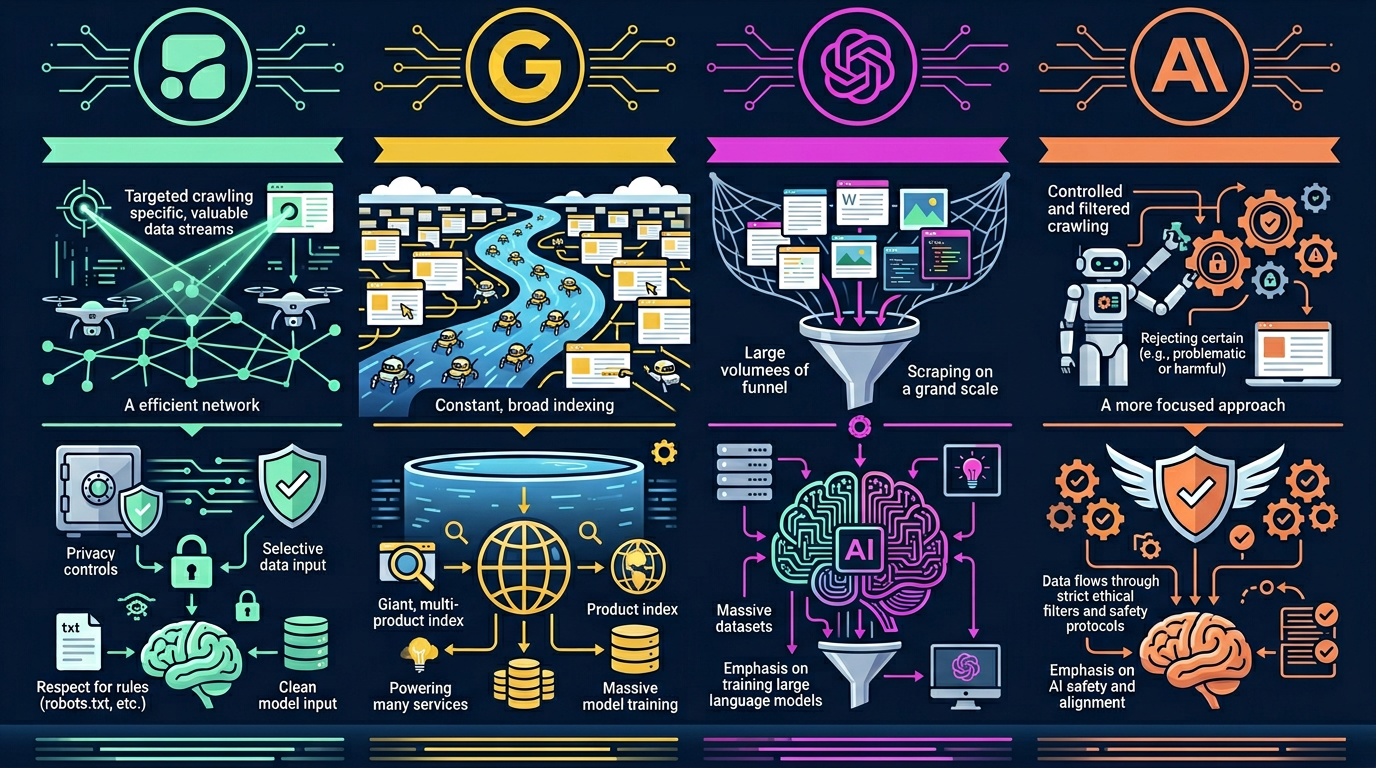
How Cohere's Crawler Compares to Other AI Crawlers
| Feature | cohere-ai | GPTBot | ClaudeBot | Google-Extended |
|---|---|---|---|---|
| Company focus | Enterprise | Consumer + API | Consumer + API | Search + AI |
| Search citations | No | No (GPTBot) | No | Yes (AI Overviews) |
| Crawl volume | Low | Medium | Low-Medium | Low |
| User base | Enterprise only | 400M+ (ChatGPT) | 50M+ (Claude) | Billions (Google) |
| Respects robots.txt | Yes | Yes | Yes | Yes |
| Server impact | Minimal | Moderate | Low | Minimal |
How to Control Cohere Crawler Access
You can control the Cohere crawler through your robots.txt file:
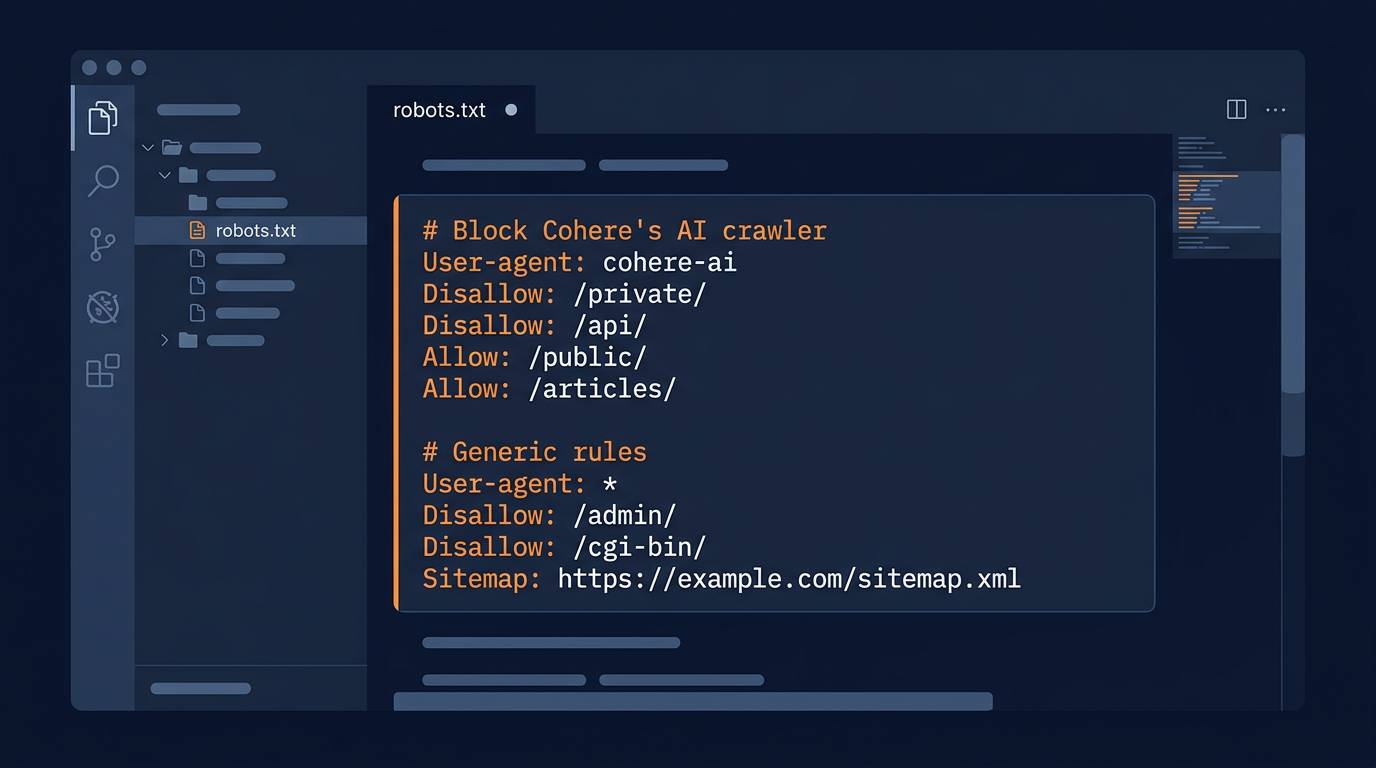
Block Cohere Crawler
Allow Cohere Crawler
Selective Access (Recommended)
Use the Robots.txt Generator for a complete configuration that includes Cohere and all other major AI crawlers.
Should You Allow or Block the Cohere Crawler?
The decision depends on your priorities:
Consider Allowing If:
You publish educational or informational content
You want your expertise in enterprise AI applications
Server load from Cohere is not a concern
You support open AI development
Your B2B clients use Cohere products
Consider Blocking If:
You have premium or licensed content
You want to minimize AI training data use
No direct benefit justifies the access
You are selectively allowing only search crawlers
Content protection is a top priority
For most website owners, Cohere's crawler falls into the "low priority" category. It does not provide direct traffic benefits like AI search crawlers, and it does not create heavy server load like aggressive crawlers. The decision is primarily about your philosophical stance on AI training data usage.
The Bigger Picture: Enterprise AI Crawlers
Cohere is not the only enterprise AI company with a web crawler. The enterprise AI crawler landscape includes several players:
Cohere (cohere-ai): Enterprise AI infrastructure for text generation, search, and classification.
Diffbot: Crawls the web to build a knowledge graph used by enterprise customers for data extraction and analysis.
AI2 (Ai2Bot): The Allen Institute for AI crawls web data for open-source research models.
Webz.io: Crawls web data to provide structured datasets for AI training and business intelligence.
To get a complete picture of which AI crawlers (both consumer and enterprise) can access your website, run a scan with the AI crawler checker online tool. It checks for 196+ AI crawlers including Cohere and other enterprise bots.
Key Takeaways
Cohere is an enterprise-focused AI company. Its crawler collects data for business AI models, not consumer search products. There is no direct traffic or citation benefit from allowing it.
The crawler is well-behaved. Cohere-ai has low crawl volume, respects robots.txt, and puts minimal load on servers. It is not an aggressive crawler.
Your decision depends on priorities. If content protection is your top priority, block it. If you support open AI development or serve B2B clients using Cohere, allow it.
Prioritize search crawlers first. Focus your AI crawler strategy on search crawlers (ChatGPT-User, PerplexityBot, Google-Extended) that provide direct traffic benefits. Enterprise training crawlers like Cohere are secondary decisions.
Use selective access if unsure. Allow Cohere access to public blog/article content while blocking premium or proprietary sections. This provides some benefit while protecting valuable content.
Check your current Cohere crawler access and all other AI bots. Use the AI crawlers analysis on our homepage to scan your robots.txt and get a complete access report. Then use the Robots.txt Generator to create the right configuration for your website.
Frequently Asked Questions
What is the Cohere AI crawler?
Is Cohere the same as OpenAI or Google?
Should I block the Cohere crawler?
Does Cohere provide citations or traffic?
How does Cohere's crawler behave?
Quick Knowledge Check
Test what you just learned. Tap "I know this" if you are confident, or "Show me" to reveal the answer.
What is the Cohere AI crawler?
Is Cohere the same as OpenAI or Google?
Should I block the Cohere crawler?
Does Cohere provide citations or traffic?
How does Cohere's crawler behave?
Was this article helpful?
Related Articles

How to Block AI Crawlers with Robots.txt (2026 Complete Guide)
A step-by-step guide to blocking (or allowing) AI crawlers like GPTBot, ClaudeBot, and Google-Extended using robots.txt. Includes code examples, best practices, and tools.
Meta-ExternalAgent: Facebook's AI Crawler Explained (2026)
Meta-ExternalAgent is Meta's AI web crawler that collects data for Llama models, Meta AI assistant, and Facebook/Instagram AI features. Learn how to control its access to your website.
How AI Crawlers Impact Your Website SEO: A Complete Analysis (2026)
A comprehensive analysis of how AI crawlers from OpenAI, Google, Anthropic, and Meta affect your website SEO, server performance, and search rankings in 2026.
Brian is the Co-founder of Horatos.ai, an AI SEO and GEO consultancy. He built AI Crawler Check to help website owners navigate the rapidly evolving landscape of AI crawlers and search. Plus, Brian has 8+ years of experience helping brands grow across Singapore, Korea, Japan, the US, and the UK. Former Head of AISEO at MediaOne Singapore. Led campaigns for Dior, HL Assurance, FXTrading, and Evoto.ai.
Check Your AI Visibility Now
Scan your website against 196+ bots and get your AI Visibility Score