Meta-ExternalAgent: Facebook's AI Crawler Explained (2026)
Meta, the company behind Facebook, Instagram, WhatsApp, and Threads, operates one of the world's largest AI research programs. Their Llama language models power the Meta AI assistant used by billions of people across Meta's platforms. To feed this massive AI ecosystem, Meta uses a web crawler called Meta-ExternalAgent that crawls websites around the world to collect training data.
For website owners, understanding Meta-ExternalAgent is important because Meta's platforms have over 3 billion monthly active users. Whether your content feeds into Meta's AI models affects how your brand and expertise appear across one of the largest digital ecosystems on the planet.
Start by checking your current status. Use the AI crawler checker online to see if Meta-ExternalAgent can currently access your website.
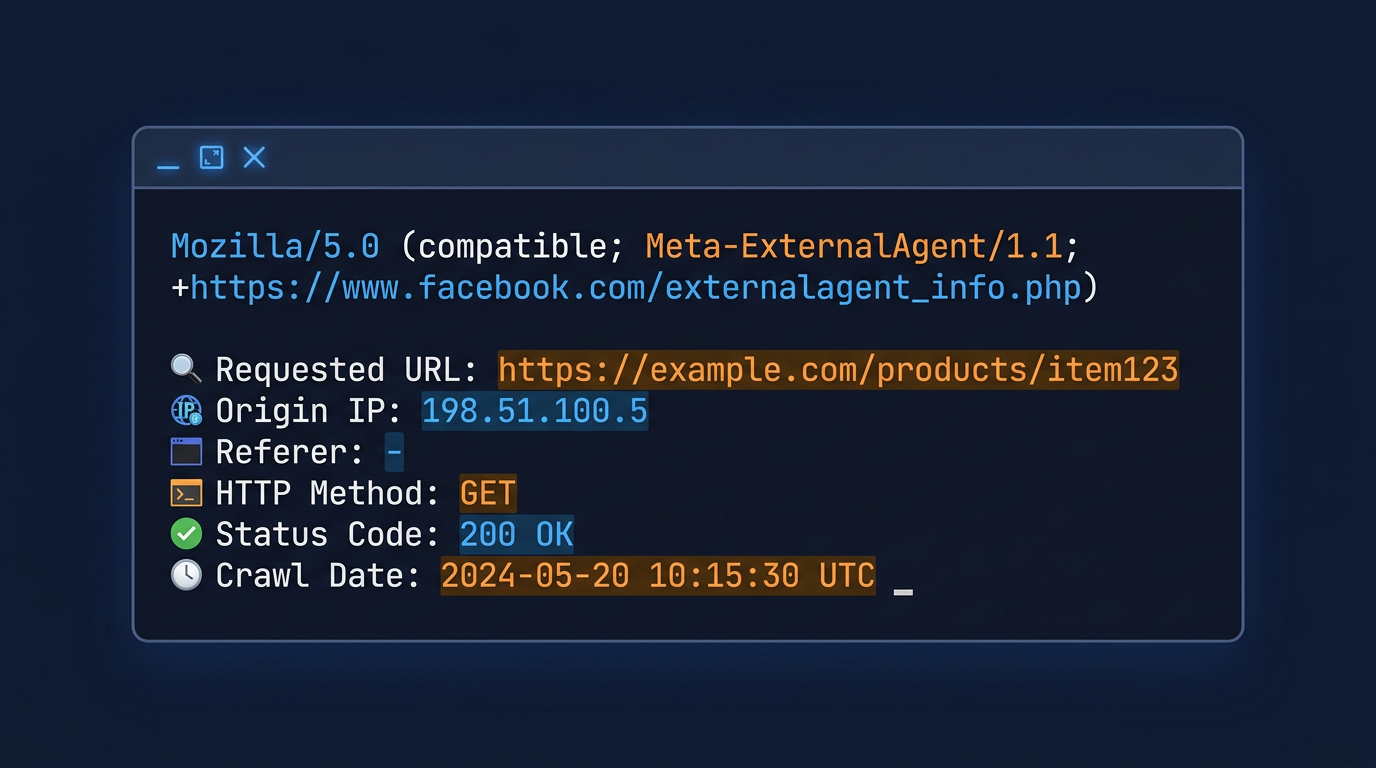
What is Meta-ExternalAgent?
Meta-ExternalAgent is Meta's official AI web crawler. It identifies itself in your server logs with the following user agent string:
Meta introduced this crawler in 2023 as their AI training data collection grew beyond what existing Facebook crawlers were designed for. Before Meta-ExternalAgent, Meta used various internal crawlers that were not well-documented. The launch of a dedicated, identifiable AI crawler was Meta's response to growing demands for transparency in AI data collection.
Meta-ExternalAgent serves several key purposes within Meta's AI infrastructure:
Llama model training: Meta's Llama family of AI models (Llama 3, Llama 4, and future versions) require massive amounts of web data for training. Meta-ExternalAgent is the primary collector of this training data.
Meta AI assistant: The Meta AI assistant available across Facebook, Instagram, WhatsApp, and Threads uses data collected by Meta-ExternalAgent to generate responses and provide information to users.
AI-powered features: Features like AI-generated summaries in Facebook News Feed, smart replies in Messenger, and content recommendations across Meta platforms all benefit from the web data collected by this crawler.
Safety and moderation: Meta uses web data to improve its content moderation AI, helping it better understand context, detect misinformation, and enforce community standards across its platforms.
Meta's Full Crawler Family
Meta operates multiple crawlers, each with a different purpose. Understanding the differences is important for making the right access decisions:
| Crawler | Purpose | Provides Citations | Crawl Volume |
|---|---|---|---|
| Meta-ExternalAgent | AI model training | No | High |
| Meta-ExternalFetcher | Real-time AI search retrieval | Sometimes | Low |
| Facebookbot | Link previews on Facebook | Yes (link previews) | Low |
| FacebookExternalHit | Open Graph metadata collection | Yes (OG previews) | Low |

What Data Does Meta-ExternalAgent Collect?
Meta-ExternalAgent crawls publicly accessible web pages and collects several types of content:
Text Content
All visible text on your web pages, including articles, blog posts, product descriptions, and comments. This text feeds directly into Llama model training data.
HTML Structure
The HTML structure of your pages, including headings, lists, tables, and semantic markup. This helps Meta's AI understand content hierarchy and meaning.
Metadata
Page titles, meta descriptions, Open Graph tags, structured data, and other metadata that provides context about your content.
Link Structure
Internal and external links on your pages. Meta uses link relationships to understand content relevance, authority, and topical connections.
Meta-ExternalAgent does not collect content behind login walls, paywalled content that requires authentication, or content in your robots.txt disallow list (it respects robots.txt rules). It also does not execute JavaScript in most cases, so dynamically loaded content may not be fully collected.
Crawl Behavior and Server Impact
Based on server log analysis from multiple websites, here is what we know about Meta-ExternalAgent's crawling behavior in 2026:
Compared to ByteSpider (which can make 3,000+ requests per day), Meta-ExternalAgent is relatively moderate in its crawling behavior. However, it can still put noticeable load on smaller websites, especially when it discovers a large site map and begins crawling many pages rapidly.
To check how Meta-ExternalAgent currently interacts with your website, use the web crawler tool free on our homepage to scan your robots.txt configuration.
Meta-ExternalFetcher: The Real-Time Companion
In addition to Meta-ExternalAgent, Meta also operates Meta-ExternalFetcher. This is a separate crawler with a different purpose:
While Meta-ExternalAgent does broad crawling for training data, Meta-ExternalFetcher retrieves specific web pages in real-time when users ask Meta AI questions that require fresh information. This is similar to how ChatGPT-User works for OpenAI's ChatGPT search feature.
For example, when a user asks Meta AI "What is the latest news about climate change?" on Facebook, Meta-ExternalFetcher may crawl relevant news sites to retrieve fresh content for the response.
The key difference for website owners is that Meta-ExternalFetcher sometimes includes source attribution. When Meta AI uses your content to answer a user question, it may link back to your page. This makes Meta-ExternalFetcher more like an AI search crawler than a training crawler.
How to Control Meta-ExternalAgent Access
You control Meta-ExternalAgent access through your robots.txt file. Here are the configuration options:
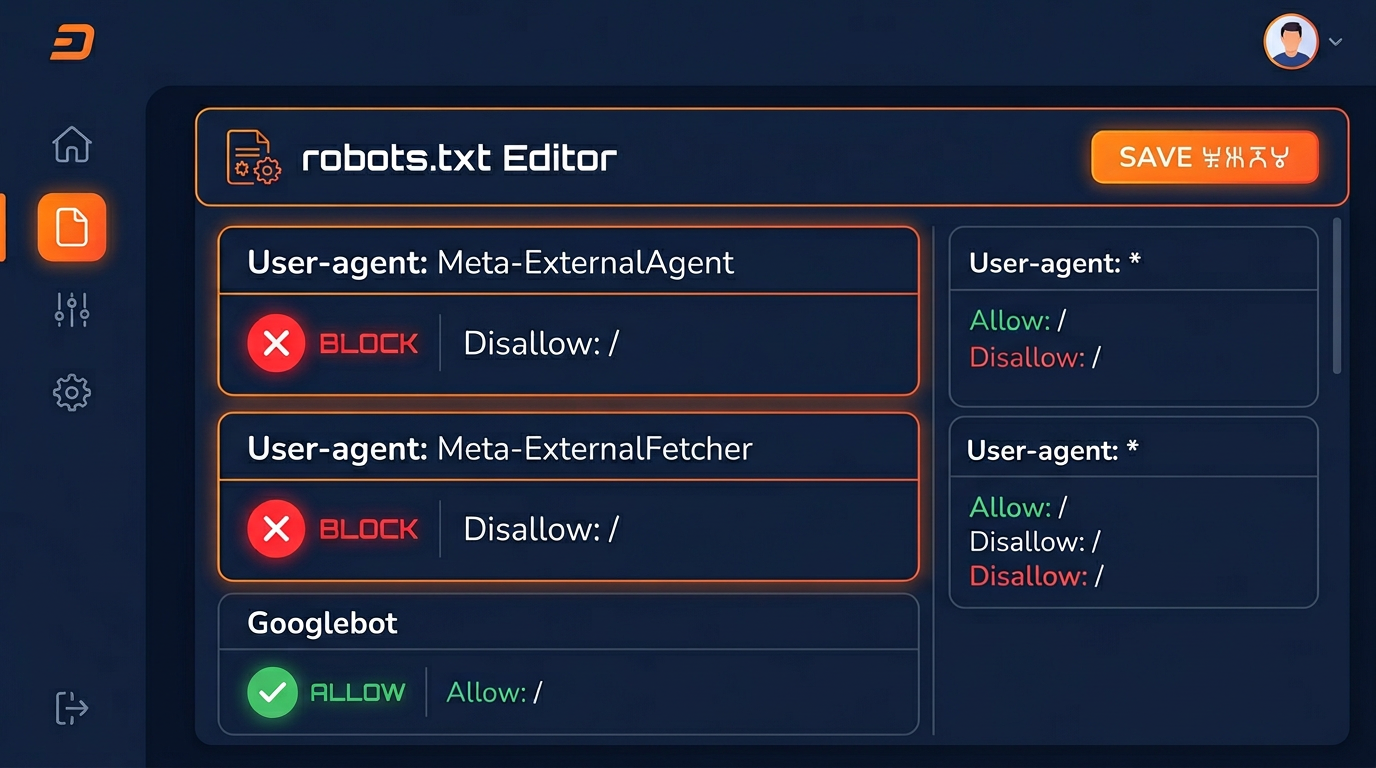
Option 1: Block All Meta AI Crawling
Option 2: Allow Meta AI Crawling
Option 3: Selective Access (Recommended)
The selective approach gives you the most control. You can allow Meta-ExternalFetcher (for potential citations in Meta AI answers) while restricting Meta-ExternalAgent to only your public blog and article content.
Use the Robots.txt Generator to create the right configuration for your website, or run a quick check with the AI crawler checker free tool.
Should You Allow or Block Meta-ExternalAgent?
The decision depends on your business goals and content strategy. Here is a framework to help you decide:
Consider Allowing If:
Your business benefits from brand visibility on Meta platforms
You want your expertise reflected in Meta AI answers
You run a public blog or information website
Your server can handle the additional crawl load
You support open AI development and data sharing
Consider Blocking If:
You have premium or paywalled content
Content licensing is part of your business model
You are concerned about AI training data rights
Your server has limited capacity
You want to protect original research or reporting
Meta-ExternalAgent vs Other AI Crawlers
How does Meta-ExternalAgent compare to other major AI crawlers? Here is a detailed comparison:
| Feature | Meta-ExternalAgent | GPTBot | ClaudeBot | ByteSpider |
|---|---|---|---|---|
| Company | Meta | OpenAI | Anthropic | ByteDance |
| Purpose | Llama training | GPT training | Claude training | TikTok AI |
| Crawl Rate | Medium | Medium | Low | Very High |
| Respects robots.txt | Yes | Yes | Yes | Mostly |
| User reach | 3B+ (Meta platforms) | 400M+ (ChatGPT) | 50M+ (Claude) | 1B+ (TikTok) |
| Citation benefit | None (training only) | None (training only) | None (training only) | None |
How to Identify Meta-ExternalAgent in Server Logs
Look for these patterns in your server access logs to identify Meta crawler activity:
Meta's crawlers typically come from IP ranges starting with 66.220.149.x and 69.63.176.x. You can verify these IPs against Meta's published crawler IP list.
For a quick overview of all AI crawlers accessing your site (including Meta's), use the AI crawlers check tool on our homepage. It scans your robots.txt and tells you exactly which bots have access.
Privacy and Data Usage Concerns
Meta's AI data collection has raised significant privacy concerns. Here is what you should know:
Legal Landscape
Several lawsuits and regulatory investigations in the EU, UK, and US are examining whether Meta's web scraping for AI training violates data protection laws. The legal landscape is still evolving.
Regional Differences
Meta has paused AI training on EU user data in some cases due to GDPR concerns. However, web crawling of publicly accessible content (not user data) continues globally.
Your Control Options
Your primary control is through robots.txt. By blocking Meta-ExternalAgent, you instruct Meta not to use your content for AI training. Meta has stated they respect robots.txt rules for their AI crawlers.
Key Takeaways
Meta-ExternalAgent is Meta's AI training crawler. It collects web data for Llama models and Meta AI features across Facebook, Instagram, WhatsApp, and Threads.
It is separate from Facebookbot. Blocking Meta-ExternalAgent does not affect your Facebook business page, ads, or link previews.
Meta-ExternalFetcher is the search companion. It retrieves content in real-time for Meta AI answers and may provide citations. Consider keeping this one allowed.
The reach is massive. Meta's platforms have 3+ billion users. Your content being in Llama models means it could influence AI responses seen by a third of the world's population.
Use selective access. The best approach for most sites is to allow Meta-ExternalFetcher while blocking or rate-limiting Meta-ExternalAgent for training.
Check your current Meta crawler access right now. Use the AI crawler checker online to scan your website and see if Meta-ExternalAgent and Meta-ExternalFetcher can access your content. Then use the Robots.txt Generator to configure the right access rules for your website.
Frequently Asked Questions
What is Meta-ExternalAgent?
How is Meta-ExternalAgent different from Facebookbot?
Should I block Meta-ExternalAgent?
Does blocking Meta-ExternalAgent affect my Facebook page?
What is Meta-ExternalFetcher?
Quick Knowledge Check
Test what you just learned. Tap "I know this" if you are confident, or "Show me" to reveal the answer.
What is Meta-ExternalAgent?
How is Meta-ExternalAgent different from Facebookbot?
Should I block Meta-ExternalAgent?
Does blocking Meta-ExternalAgent affect my Facebook page?
What is Meta-ExternalFetcher?
Was this article helpful?
Related Articles

How to Block AI Crawlers with Robots.txt (2026 Complete Guide)
A step-by-step guide to blocking (or allowing) AI crawlers like GPTBot, ClaudeBot, and Google-Extended using robots.txt. Includes code examples, best practices, and tools.

What is GPTBot? OpenAI's Web Crawler Explained (2026)
Everything you need to know about GPTBot, OpenAI's web crawler for ChatGPT training. User-agent string, blocking rules, impact on SEO, and how it compares to other AI crawlers.
How AI Crawlers Impact Your Website SEO: A Complete Analysis (2026)
A comprehensive analysis of how AI crawlers from OpenAI, Google, Anthropic, and Meta affect your website SEO, server performance, and search rankings in 2026.
Brian is the Co-founder of Horatos.ai, an AI SEO and GEO consultancy. He built AI Crawler Check to help website owners navigate the rapidly evolving landscape of AI crawlers and search. Plus, Brian has 8+ years of experience helping brands grow across Singapore, Korea, Japan, the US, and the UK. Former Head of AISEO at MediaOne Singapore. Led campaigns for Dior, HL Assurance, FXTrading, and Evoto.ai.
Check Your AI Visibility Now
Scan your website against 196+ bots and get your AI Visibility Score