
Why AI Bots Can't Crawl Your Website (and How to Fix It)
You have great content. Your SEO is solid. Your website ranks on Google. But when people ask ChatGPT or Perplexity about your industry, your website never gets mentioned. Why?
The most common reason is simple: AI bots cannot access your website. Before any AI engine can cite your content, its crawler needs to read your pages. If something blocks that crawler, your website is invisible to AI search, no matter how good your content is.
Based on our experience analyzing thousands of websites with the AI Crawler Check tool, here are the 7 most common reasons AI bots cannot crawl your website, and the exact steps to fix each one.
Quick Diagnostic
Before reading further, run a free AI crawler check on your website. It takes 10 seconds and shows you exactly which AI bots are blocked and why. Then come back to this guide for the fix.
Reason 1: robots.txt Blocks AI Crawlers
This is the #1 cause. Your robots.txt file contains rules that specifically block AI crawlers, or uses a broad wildcard rule that blocks them unintentionally.
How This Happens
Common patterns we see in robots.txt files:
# This blocks ALL bots including AI crawlers
User-agent: *
Disallow: /
# This specifically blocks major AI bots
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /Sometimes website owners add these rules intentionally when they first heard about AI crawlers in 2024, before AI search became important. Other times, a developer or plugin added them without the owner's knowledge.
How to Fix
- Check your robots.txt with the AI Crawler Check tool to see which bots are blocked
- Edit your robots.txt to allow the AI search bots you want. See our robots.txt creation guide for the recommended configuration
- Use the Robots.txt Generator tool to create an optimized robots.txt file
- Upload the new robots.txt to your website root directory
# Recommended: allow AI search bots
User-agent: GPTBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /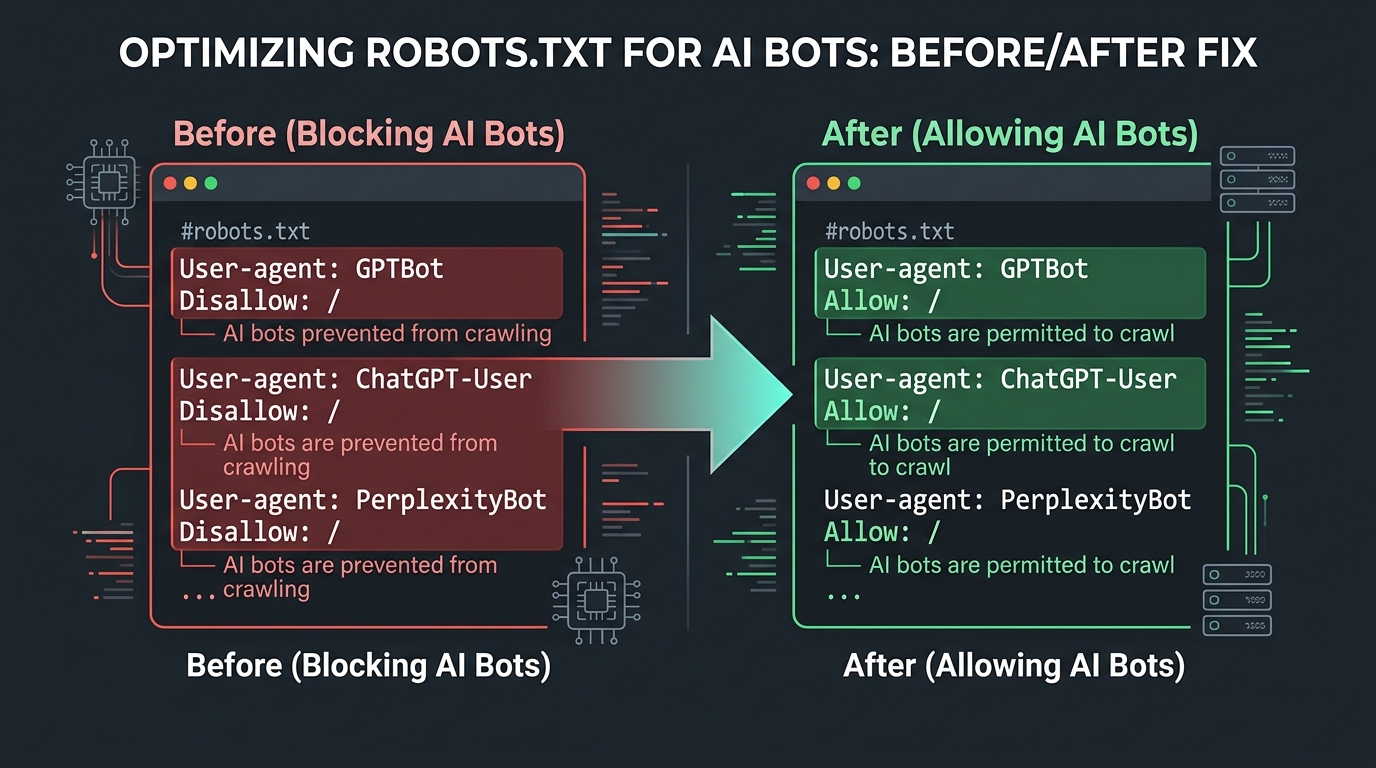
Reason 2: Cloudflare or CDN Firewall Blocking
This is the sneakiest cause because your robots.txt might say "Allow" but the firewall blocks AI bots before they can even read it.
How This Happens
If your website uses Cloudflare, Sucuri, Imperva, or another WAF (Web Application Firewall), these services can block AI bot requests with a 403 Forbidden response or a JavaScript challenge page. The most common causes:
- Bot Fight Mode: Cloudflare's automated bot detection may classify AI crawlers as unwanted bots
- WAF rules: Custom firewall rules that block non-browser user agents
- JavaScript challenges: CAPTCHA or challenge pages that bots cannot solve
- Rate limiting: Overly aggressive rate limiting that throttles all bot traffic
How to Detect
The AI Crawler Check tool includes WAF detection. If your robots.txt says bots are allowed but the tool reports a WAF block, you will see a yellow warning banner. You can also check your Cloudflare analytics for blocked requests from known AI bot user agents.
How to Fix
For Cloudflare:
- Go to Security > Bots in your Cloudflare dashboard
- In the "Configure Super Bot Fight Mode" section, set "Verified Bots" to "Allow"
- Create WAF custom rules to allow known AI bot user agents (GPTBot, ClaudeBot, PerplexityBot)
- Check Security > Events to verify AI bots are no longer being challenged
For other WAFs: Add AI bot user agents to your allowlist. Consult your WAF provider's documentation for specific instructions.
Reason 3: CMS or Plugin Default Settings
Many CMS platforms and security plugins block AI crawlers by default. You may not even know these settings exist.
Common Offenders
- WordPress + Wordfence: Wordfence can block AI crawlers based on user agent patterns
- WordPress + Sucuri: Sucuri's WAF may challenge or block bot-like requests
- Shopify: Some Shopify apps add restrictive robots.txt rules
- Wix: Custom security settings can block non-standard crawlers
- Squarespace: Limited robots.txt customization may accidentally block AI bots
How to Fix
- Check your security plugin settings for bot-blocking options
- Look for "Block AI Crawlers" or "Block GPTBot" toggles and disable them
- Review your CMS robots.txt editor for any auto-generated blocking rules
- After making changes, re-run the AI crawler check to verify
Reason 4: Server-Level IP Blocking
Some hosting providers or server configurations block requests from data center IP addresses, which is where AI crawlers operate from.
How This Happens
Server firewalls (iptables, fail2ban, .htaccess rules) may block IP ranges associated with cloud providers like AWS, Google Cloud, or Microsoft Azure. AI crawlers run from these data centers, so they get blocked even though the robots.txt allows them.
How to Fix
- Whitelist known AI bot IP ranges (OpenAI publishes their IP ranges publicly)
- Review server firewall rules for overly broad IP blocks
- Check .htaccess for deny rules that might catch AI bot IPs
- Contact your hosting provider if you cannot access firewall settings
Reason 5: JavaScript-Only Content
If your website's content is rendered entirely by JavaScript (single-page applications, heavy React/Vue/Angular apps), some AI crawlers may not be able to see it.
How This Happens
Some AI crawlers do not execute JavaScript. When they fetch your page, they only see the initial HTML response, which might be empty or contain just a loading spinner. Your actual content, loaded by JavaScript after the page renders, is invisible to these crawlers.
How to Fix
- Server-side rendering (SSR): Use Next.js, Nuxt.js, or similar frameworks that render HTML on the server
- Static site generation (SSG): Pre-build HTML pages at build time
- Hybrid approach: Ensure critical content (headings, main text, FAQs) is in the initial HTML
Reason 6: noindex or Meta Robots Restrictions
Even if AI bots can reach your pages, meta robots tags or X-Robots-Tag headers might tell them not to use the content.
Common Restrictions
<!-- This tells ALL bots not to index the page -->
<meta name="robots" content="noindex, nofollow">
<!-- This specifically targets AI bots -->
<meta name="GPTBot" content="noindex">
<!-- X-Robots-Tag in HTTP headers -->
X-Robots-Tag: noindex, nofollowHow to Fix
- Check your page source code for meta robots tags
- Check HTTP response headers for X-Robots-Tag
- Remove any noindex tags that were added accidentally
- If you use WordPress, check your SEO plugin settings (Yoast, Rank Math) for noindex pages

Reason 7: Missing AI Discoverability Signals
Even when AI bots can access your content, they might not prioritize it if you are missing key signals that help them understand and trust your website.
Missing Signals That Reduce AI Visibility
- No llms.txt file: AI engines cannot quickly understand your site's purpose and authority. Create one now.
- No structured data: Missing schema markup means AI engines have to guess the context of your content
- No sitemap.xml: Without a sitemap, AI crawlers may not discover all your important pages
- Weak E-E-A-T signals: No author pages, no credentials, no original data
How to Fix
Follow the AI SEO audit checklist to add these signals systematically. The AI Crawler Check tool already checks for llms.txt and llms-full.txt. If those files are missing, your AI Visibility Score takes a hit.
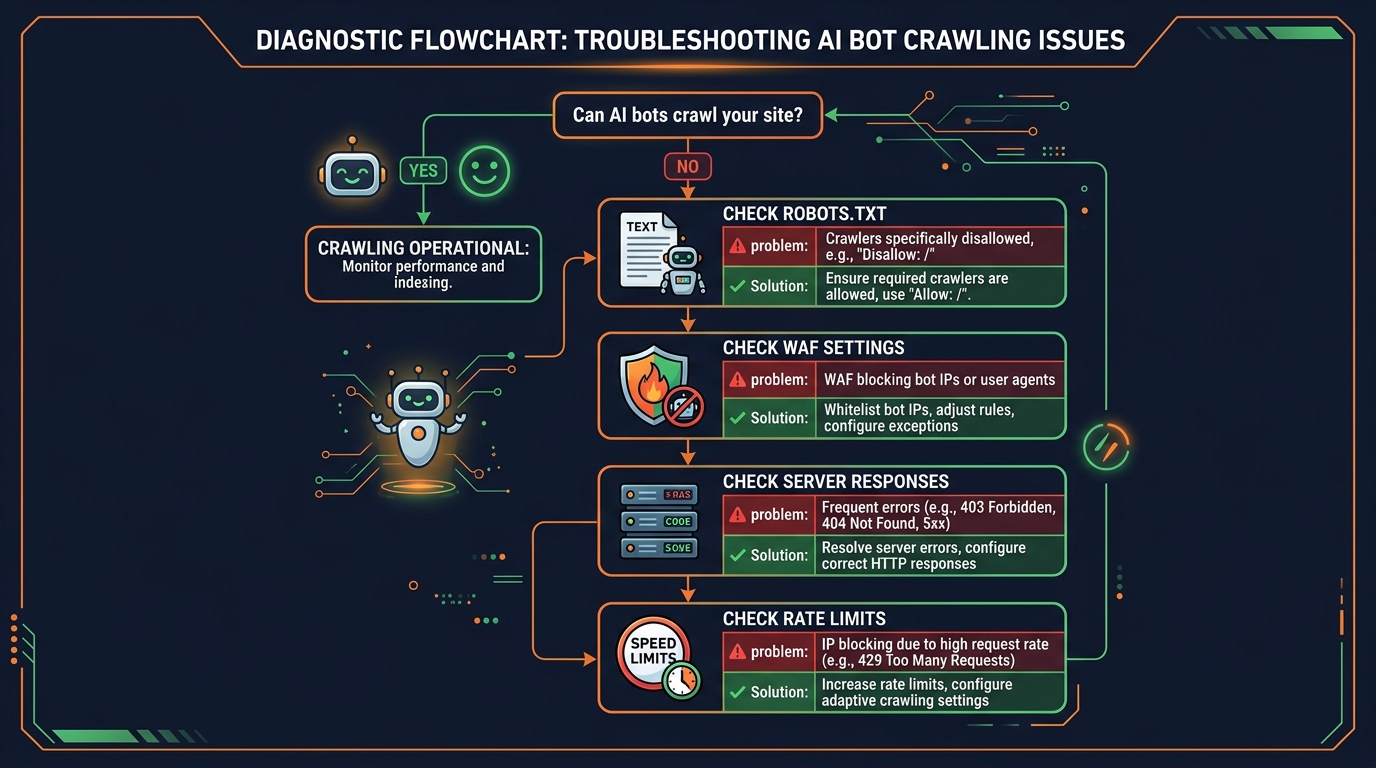
Complete Diagnostic Checklist
Use this checklist to systematically diagnose why AI bots cannot crawl your website:
Get your AI Visibility Score and see which bots are blocked
Check robots.txt for blocking rules
Look for Disallow: / under AI bot user agents or User-agent: *
Check WAF/CDN settings
Verify Cloudflare Bot Fight Mode is not blocking AI bots
Review security plugin settings
Check Wordfence, Sucuri, or other plugins for bot-blocking features
Verify content is in HTML (not JS-only)
View page source to check if content is in the initial HTML response
Check meta robots and X-Robots-Tag
Look for noindex, nofollow tags in page source and HTTP headers
Add missing AI discoverability signals
Create llms.txt, add schema markup, submit sitemap
Re-run the AI Crawler Check to verify fixes
Confirm your AI Visibility Score has improved
What Happens After You Fix AI Bot Access
Once you have removed the barriers, here is what to expect:
Week 1 to 2: Bots Start Crawling
AI crawlers will start visiting your website. You can verify this in your server logs and analytics.
Week 2 to 4: Content Gets Indexed
AI engines process and index your content. They start including it in their knowledge base.
Month 2+: Citations Begin
If your content has strong E-E-A-T signals and answers questions clearly, AI engines will start citing you in generated answers.
Remember: fixing bot access is necessary but not sufficient. You also need:
- High-quality, expert content with original insights
- Strong E-E-A-T signals (author credentials, original data)
- Proper structured data
- An llms.txt file for AI discoverability
- A solid GEO + SEO strategy
Conclusion: Don't Let Technical Issues Make You Invisible
AI search is growing fast. ChatGPT, Perplexity, and Google AI Overviews now answer millions of queries daily. Every query where your website could be cited but is not is a missed opportunity for traffic, brand awareness, and authority.
The good news: most AI bot access issues have simple fixes. The bad news: you might not even know you have a problem. That is why the first step is always the same.
Take Action Now
Run a free AI Crawler Check on your website
Enter your domain, get your AI Visibility Score, and see exactly which of the 196+ AI bots are blocked. It takes 10 seconds. Then use this guide to fix any issues.
For a complete optimization plan, check our other guides:
Frequently Asked Questions
How do I know if AI bots are blocked on my website?
Why would my website block AI bots by default?
Should I allow all AI bots on my website?
Will fixing AI bot access immediately improve my AI visibility?
Can my Cloudflare or CDN settings block AI bots?
Quick Knowledge Check
Test what you just learned. Tap "I know this" if you are confident, or "Show me" to reveal the answer.
How do I know if AI bots are blocked on my website?
Why would my website block AI bots by default?
Should I allow all AI bots on my website?
Will fixing AI bot access immediately improve my AI visibility?
Can my Cloudflare or CDN settings block AI bots?
Was this article helpful?
Related Articles

How to Block AI Crawlers with Robots.txt (2026 Complete Guide)
A step-by-step guide to blocking (or allowing) AI crawlers like GPTBot, ClaudeBot, and Google-Extended using robots.txt. Includes code examples, best practices, and tools.

AI Crawler Rate Limiting: How to Control Bot Traffic on Your Site (2026)
AI crawlers can consume significant server resources. Learn how to rate limit bot traffic using robots.txt crawl-delay, nginx configuration, WAF rules, and monitoring tools.
How to Create a robots.txt File for AI Bots: Step-by-Step (2026)
A complete beginner-friendly tutorial for creating a robots.txt file to manage AI crawlers. Includes copy-paste templates for common scenarios, testing methods, and platform-specific instructions.
Brian is the Co-founder of Horatos.ai, an AI SEO and GEO consultancy. He built AI Crawler Check to help website owners navigate the rapidly evolving landscape of AI crawlers and search. Plus, Brian has 8+ years of experience helping brands grow across Singapore, Korea, Japan, the US, and the UK. Former Head of AISEO at MediaOne Singapore. Led campaigns for Dior, HL Assurance, FXTrading, and Evoto.ai.
Check Your AI Visibility Now
Scan your website against 196+ bots and get your AI Visibility Score